Do Deep Nets Really Need to be Deep?
Do Deep Nets Really Need to be Deep? Training Shallow Nets to Mimic Deep Nets Model CompressionMimic Learning via Regressing Logit with L2 Loss Speeding-up Mimic Learning by Introducing a Linear LayerDiscussionWhy Mimic Models Can Be More Accurate than Training on Original Labels The Capacity and Representational Power of Shallow Models Summary
Training Shallow Nets to Mimic Deep Nets
Model Compression
文章说的很清楚,模型压缩的主要方法在于训练一个Compact Model(小模型)去近似更大的模型学习到的函数。模型压缩是通过把数据输入到Teacher模型中(大模型),收集输出的Scores,然后把这些Scores当作标签数据,用于训练Student Model。不使用原始标签数据训练小模型的原因在于当前的学习算法容易出现过拟合问题,学习到的结果不如复杂模型也不如mimic model。因此必须要训练复杂的中间模型,然后训练小模型去mimic。很明显,如果可以用一个小网络去mimic复杂模型学习到的函数,那么这个学习到的函数必然不会很复杂。这暗示了我们,学习好的模型的复杂性和学习到的表示空间的大小并不是一个东西。在这篇文献中,作者把模型压缩用于训练浅层神经网络去mimic深层神经网络,因此证明了deep neural nets may not need to be deep。
Mimic Learning via Regressing Logit with L2 Loss
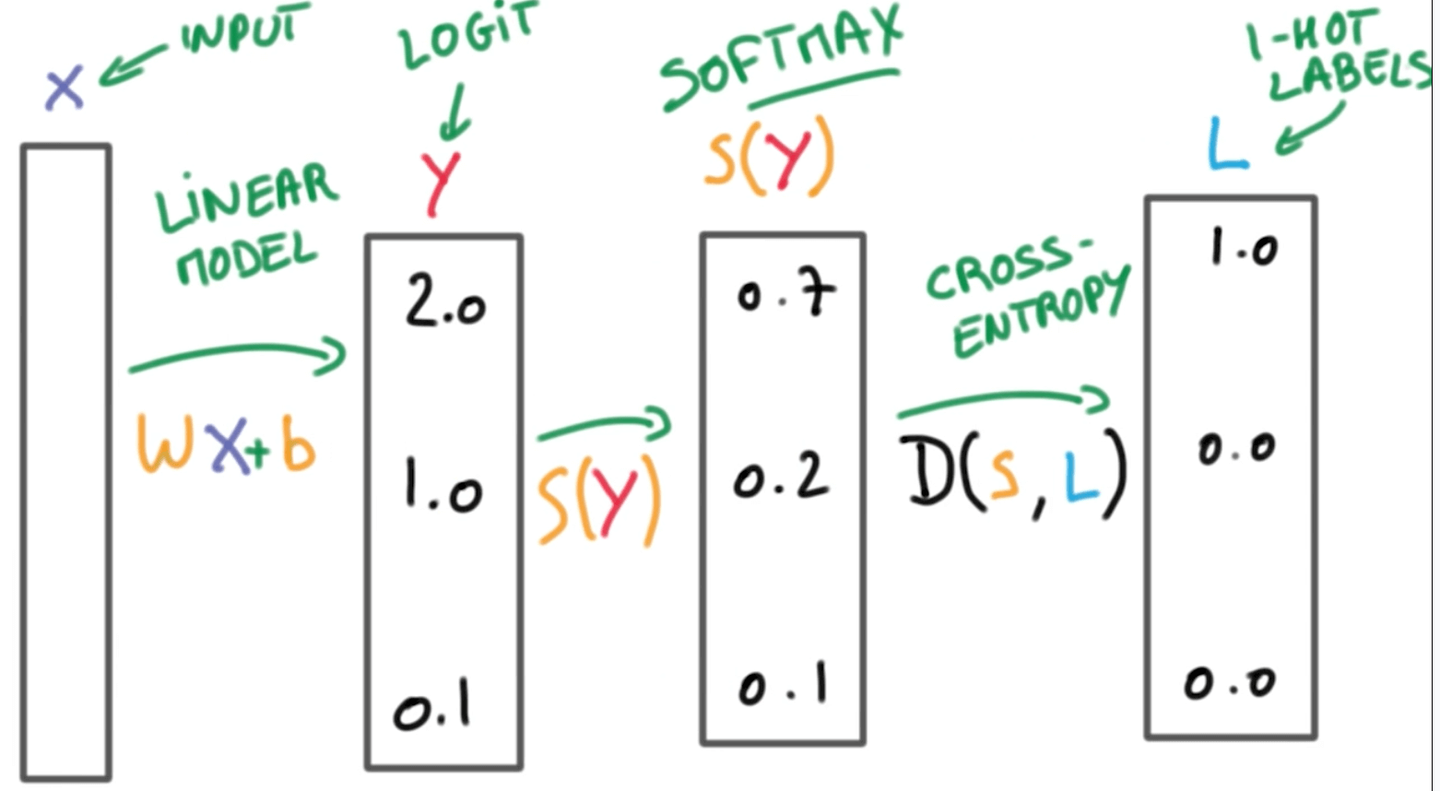
训练Student Model不使用Teacher Model直接输出的Softmax结果,而是使用Softmax之前的Logit。文章举了两个例子说明为什么使用Logit:第一,当teacher预测出概率,如果使用这个作为预测目标,那么Student Model很容易忽略第一个和第二个与第三个之间的关系,而实际上的Logits可能是,这样之间的difference就显现出来了;第二,Logits 经过Softmax的结果和上面那个例子一样,但是明显和表示的关系是不一样的。
By training the student model on the logits directly, the student is better able to learn the internal model learned by the teacher, without suffering from the information loss that occurs after passing through the logits to probability space.
文中给出了最终的learning objective function,作为一个回归问题 :
The parameters W and β are updated using standard error back-propagation algorithm and stochastic gradient descent with momentum.
文章也实验了其他mimic loss function,比如, ,效果都不如上面的,并且归一化效果不大,并不关键。
Speeding-up Mimic Learning by Introducing a Linear Layer
如果只使用单个隐藏层,那么Input Layer和Hidden Layer之间的权重矩阵大小为,H和D可能都很大,所以很多计算都用在了权重矩阵和输入向量的乘积上。文中引入了一个bottleneck linear layer,大小为k个线性隐藏单元,放置于Input和Hidden Layer之间,这样将权重矩阵分解为和。新的损失函数为:
这样不仅提高了收敛速率更是减少了内存消耗,可以构造更大的浅层网络。The linear bottle neck can only reduce the representational power of the network, and it can always be absorbed into a single weight matrix W.
Discussion
Why Mimic Models Can Be More Accurate than Training on Original Labels
- if some labels have errors, the teacher model may eliminate some of these errors ( i.e. , censor the data), thus making learning easier for the student: on TIMIT, there are mislabeled frames introduced by the HMM forced-alignment procedure.
- if there are regions in the that are difficult to learn given the features, sample density, and function complexity, the teacher may provide simpler, soft labels to the student. The complexity in the data set has been washed away by filtering the targets through the teacher model.
- learning from the original hard 0/1 labels can be more difficult than learning from the teacher’s conditional probabilities: on TIMIT only one of 183 outputs is non-zero on each training case, but the mimic model sees non-zero targets for most outputs on most training cases. Moreover, the teacher model can spread the uncertainty over multiple outputs when it is not confident of its prediction. Yet, the teacher model can concentrate the probability mass on one (or few) outputs on easy cases. The uncertainty from the teacher model is far more informative to guiding the student model than the original 0/1 labels. This benefit appears to be further enhanced by training on logits
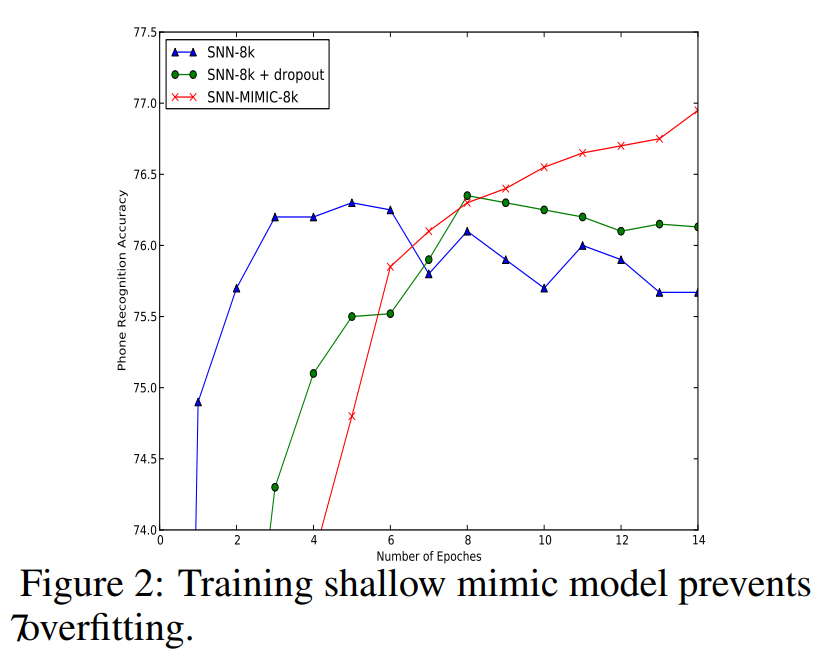
这种机制可以被视作正则化的一种方式。模型压缩可能就是用来消除浅层网络和深层网络gap的一种正则化手段。
The Capacity and Representational Power of Shallow Models
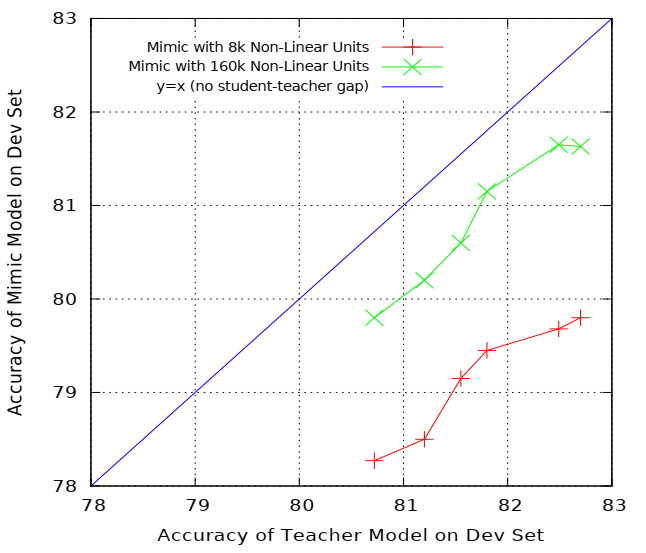
我们可以看到随着Teacher Model准确率的上升,Mimic Model准确率也在上升,红线和绿线之间的gap是由于网络参数规模的差别,但是可以看到随着Teacher Model准确率上升,红线也能达到绿线的水平,所以并没有证据表明,浅层模型有有限的表示能力,相反主要的限制出现在训练浅层模型的学习和正则化过程。
Summary
- This approach allows one to adjust flexibly the trade-off between accuracy and computational cost
- Developing algorithms to train shallow models of high accuracy directly from the original data without going through the intermediate teacher model would, if possible, be a significant contribution.
- For a given number of parameters, depth may make learning easier, but may not always be essential.